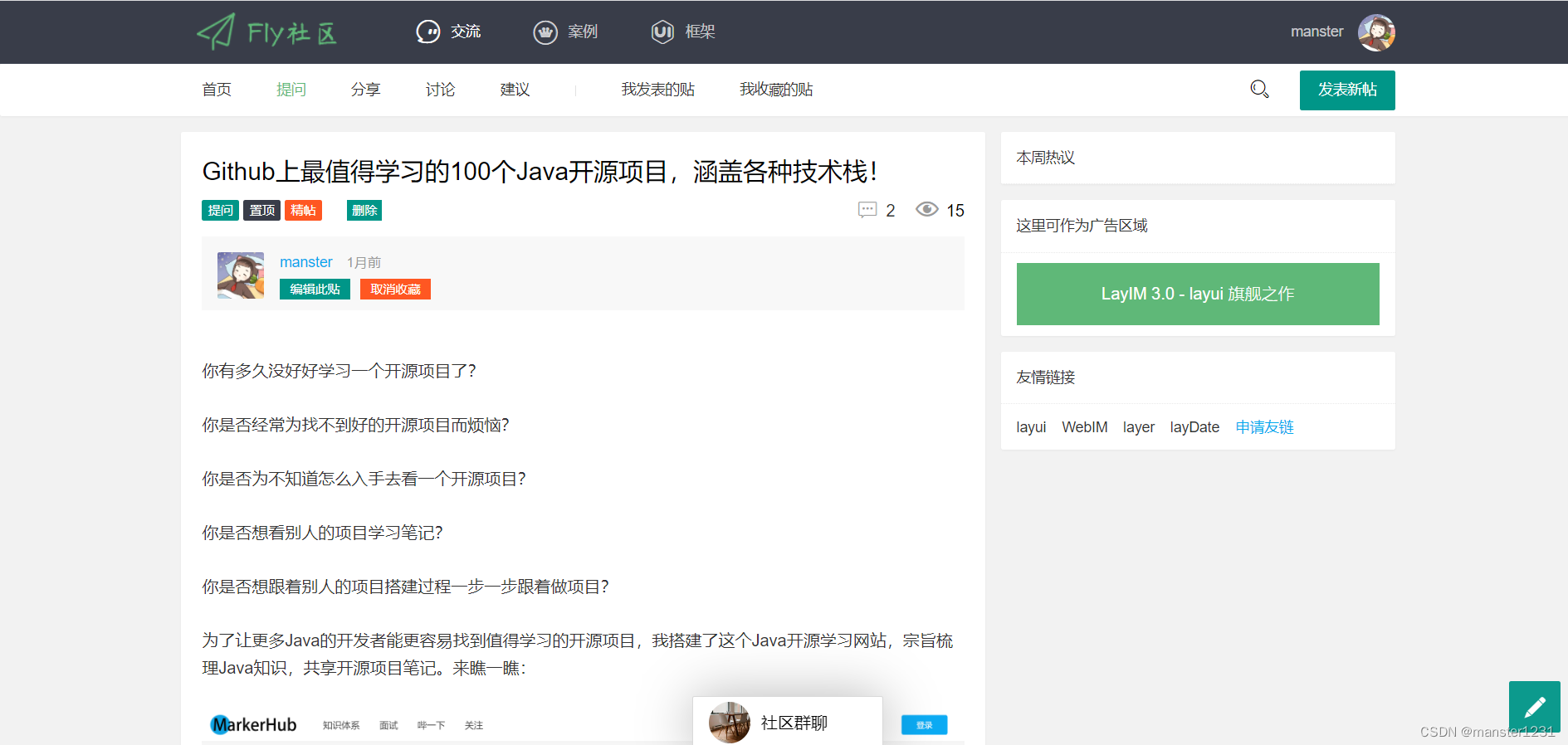
基于 SpringBoot + FreeMarker 开发的博客论坛项目。前端使用 layui + fly 模板,使用自定义 Freemarker 标签,使用 shiro+redis 完成了会话共享,redis 的 zset 结构完成本周热议排行榜,t-io+websocket 完成即时消息通知和群聊,rabbitmq+elasticsearch 完成博客内容搜索引擎,使用 mybatis plus 方便数据库操作,使用 mysql 作为数据库。

前端
- 登录注册
- 文章管理
- 评论管理
- 收藏、精选、置顶
- 搜索
- 个人中心
- 群聊
安装 rabbitmq https://blog.csdn.net/qq_45803593/article/details/124922690
安装 elasticsearch https://blog.csdn.net/qq_45803593/article/details/124895016
1、自定义 freemarker 方法
我们想要博客在显示时间的时候,将时间显示为 秒前;分钟前;小时前;天前;月前;年前;未知;
1、导入工具类包
2、导入模板工具类
DirectiveHandler
TemplateDirective
TemplateModelUtils
3、自定义方法
4、将方法注入到 freemarker 中
作用: @PostConstruct注解的方法在项目启动的时候执行这个方法,也可以理解为在spring容器启动的时候执行,可作为一些数据的常规化加载,比如数据字典之类的。
执行顺序: 其实从依赖注入的字面意思就可以知道,要将对象p注入到对象a,那么首先就必须得生成对象a和对象p,才能执行注入。所以,如果一个类A中有个成员变量p被@Autowried注解,那么@Autowired注入是发生在A的构造方法执行完之后的。
如果想在生成对象时完成某些初始化操作,而偏偏这些初始化操作又依赖于依赖注入,那么久无法在构造函数中实现。为此,可以使用@PostConstruct注解一个方法来完成初始化,@PostConstruct注解的方法将会在依赖注入完成后被自动调用。
Constructor >> @Autowired >> @PostConstruct
FreeMarkerConfig
2、自定义 freemarker 标签
1、自定义标签
2、配置标签
3、使用标签
common.ftl 首先我们将一篇博客的简要信息进行封装
index.ftl 然后我们将获取到的列表进行遍历
3、redis 的 zset 实现排行榜
1、redis操作分析
我们需要使用的 redis 命令有:
- 新增:ZADD key score member
- 自增:ZINCRBY key increment member
- 并集:ZUNIOnSTORE key numkeys key [key …]
- 排序:ZREVRANGE key 0 -1 withscores
使用 redis 的有序聚合 zset 来进行排行榜的统计,我们将每七天作为一个周期来进行排序
首先我们将每天的评论数量进行存储,其对应的 redis 命令为
然后我们完成七天每篇博客的评论数相加,其形式应该为
这里我们需要使用并集,将集合中相同的成员的值进行相加合并
Redis Zunionstore 命令计算给定的一个或多个有序集的并集,其中给定 key 的数量必须以 numkeys 参数指定,并将该并集(结果集)储存到 destination 。
默认情况下,结果集中某个成员的分数值是所有给定集下该成员分数值之和 。
使用 WEIGHTS 选项时,可以为各个有序集合输入指定一个乘法系数(Multiplication factor )。这意味着在将每个有序集合输入中的每个元素的分值传递给聚合函数(Aggregation function)之前,会将该分值乘以对应的系数。当未给定 WEIGHTS 选项时,乘法系数默认为 1。
使用 AGGREGATE 选项时,可以指定并集运算结果的聚合方式。该选项默认值为 SUM,即将输入中所有存在该元素的集合中对应的分值全部加一起。当选项被设置为 MIN 或 MAX 任意值时,结果集合将保存输入中所有存在该元素的集合中对应的分值的最小或最大值。
我们这里需要进行的操作就是七个集合进行并集
最终我们的测试命令集合为
至此我们就得到了我们想要的结果
2、项目代码实现
1、初始化数据
首先我们需要在项目启动以后就将数据进行初始化,所以我们还是写在 ContextStartup 中,同时我们需要实现 redis 序列化,不适用java 默认的序列化方式
我们在项目启动时就将近7天的数据进行初始化
然后我们在 blog 服务中实现初始化,
- 首先我们查出 7 天内发布的所有文章
- 然后设置每天日期为 key,评论数为 score,文章id 为 member;同时设置过期时间
- 设置完成后我们将这些文章的简要信息都存入一个 hash 中
- 最后我们对这 7 天的每篇文章的评论数做一个并集得出排行榜
测试结果如下
2、获取本周热议
这里我们还是使用自定义标签的方式来进行获取
FreeMarkerConfig 然后我们在配置类中增加这个标签
right.ftl
3、增加评论数
接下来我们需要做的就是在增加评论的时候将这篇文章的评论数+1,同步到 redis 中并且重新进行并集计算。
- 在我们的缓存中,启动时就缓存了近7天内发布的文章,但是新增的评论的文章可能是之前没有的,所以我们还需要注意
3、文章阅读量同步
我们将文章的阅读量进行缓存,避免过多的操作数据库,但是也要定时将数据同步到数据库里面
1、缓存阅读量
每当我们请求博客详情时,我们就执行这个操作
BlogController
2、同步数据
我们需要做一个定时器来将其同步到数据库中
4、及时通知作者评论内容
1、回复评论
2、导入 webscoket
因为评论后我们会发送消息给作者或者@的用户,为了即时通知,我们需要使用 websocket
然后我们配置 websocket
在前端页面也进行添加,在登陆后加载 websocket,我们需要在 layout.ftl 先导入 、
然后我们编写 js 来加载 websocket
- 当我们发送消息到 这个通道的时候,前端就可以实时收到消息进行展示
3、发送消息
创建 WebSocketService,WebSocketServiceImpl 来实现消息发送
5、elasticsearch 实现搜索功能
1、简介
结合我们学习过的内容,我们之前学习搜索引擎,学过 lucene 还有 elasticsearch,lucene 比较适合单体项目,不适合分布式。
对于数据之间的同步,比如修改或者删除了数据,es是基于内存的,我们需要通知它来进行相应数据的同步,我们就需要加入一些别的中间件来通知进行同步了,有以下三种方案:
- elasticsearch + RabbitMq
- elasticsearch + canal
- elasticsearch + logstash
这次搜索我们用的是 es,es 与数据库之间的内容同步我们用的是 RabbitMq 进行一步同步。下面我们一一来实现这些功能。
首先我们来分析一下我们要开发的功能。
- 搜索功能
- es 数据初始化
- es 与数据库的异步同步功能
集成 elasticsearch 的方式有很多,
- 比较原生的 TransportClient client
- spring 提供的 ElasticsearchTemplate
- spring jpa 提供的 ElasticsearchRepository
其中使用 ElasticsearchRepository 应该是开发量最小的一种方式,使用 template 或者 TransportClient client 方式可能会更灵活。
我们之前有学过 spring data jpa,一种可以按照命名规则就可以查库的方式,在搜索单表时候特别方便。
这次开发,我们使用 ElasticsearchRepository 的方式,当然,引入了这个包之后,你也可以使用 ElasticsearchTemplate 来开发。spring 都会自动帮你注入生成。
2、配置
1、首先我们导入 jar
windows下安装 elasticsearch
- 6.4.3 版本的下载地址:www.elastic.co/cn/download…
- 安装教程:https://www.jianshu.com/p/fc1d9f6b7de2
2、然后我们对 es,rabbitmq 进行配置
在这里,可能会产生一个依赖冲突,因为 redis 和 es 底层都要依赖 netty,当这两个依赖的 netty 版本不一致的时候就会产生冲突,对此我们在启动类中加入
3、前端分析
首先我们分析一下前端代码 mods/index.js
- 我们可以看出它是弹个窗跳到了 bing 去进行搜索
- 我们将其进行修改为直接写一个 /search 接口,而关键字 name 为 q
- 我们注释掉搜索后的前缀值
4、接口编写
然后我们进行接口的编写
我们返回一个 search 页面,就照着 index 页面即可,这里要注意我们封装的分页组件请求路径后面直接拼接 pn,但是我们这里还需要原来的 q 查询关键字条件,所以我们不直接使用组件了,而是根据这个页面的特点来重新写请求路径
5、搜索类
1、实体
我们将所有关于搜索的东西都放在 search 包下,首先我们需要一个 model 类来存储 es 对象
- 表示使用 ik 分词器
- 表明这是一个关键字分词,不需要进行切分分词
2、持久
我们还需要持久层操作,repository,这里就使用符合 JPA 命名规范的操作语法就可以进行操作了
这时,我们就可以启动 head 插件来看一下是否启动是就帮助我们创建了 Blog 的 index(类似于数据库)
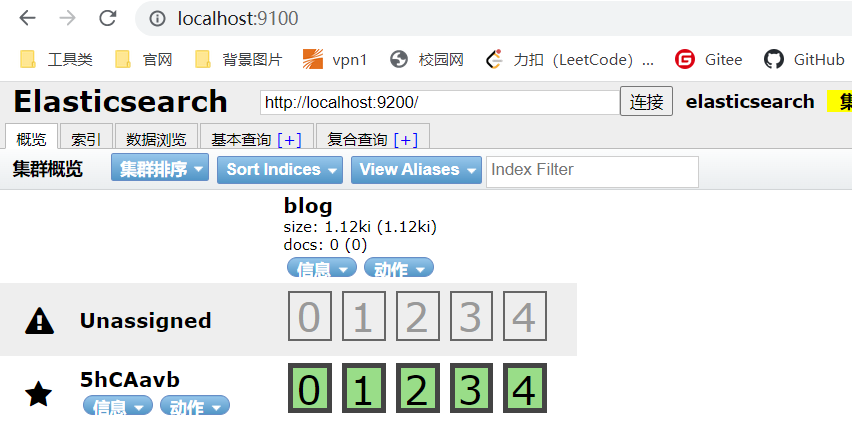
6、实现搜索
1、搜索
我们创建 SearchService 以及其实现类,并将其注入到 baseController 中
然后我们实现 search 方法
2、全量同步
在项目启动的时候,我们就将全部博客信息都存入 es 中,在这里我们决定给管理员一个同步的按钮,让其进行同步
AdminController
初始化操作 SearchServiceImpl
前端增加一个按钮
此时我们就可以实现数据的同步与搜索了
6、rabbitmq 实现 es 数据同步
1、配置mq
当将文章进行编辑以后,我们将其更新到 es 中,所以我们首先要对 rabbitmq 进行配置
当我们发送一条消息到交换机 es_exchange 并指定 RoutingKey 为 es_exchange 后,会把消息存到队列 es_queue 里面,然后我们的消费者监听到队列消息后我们就可以进行消费了。
2、生产消息
然后我们就需要定义发送包含什么内容的消息到消息队列
然后我们就在修改博客时发送消息
3、消费消息
然后我们对消息进行消费
然后我们实现这两种消息的消费
至此,我们的同步到 es 的目的就到达了
7、群聊
1、群聊Demo
今天就来完成一个聊天室的功能。
技术选型:
- 前端 layim、websocket
- 后端 t-io websocekt 版
首先我们先来把 layim 的界面先运行起来。layim 是 layui 的一个付费模块,首先我们把 layui 的静态资源包放到 static 中,关于 layim,因为不是完全开源的产品,所以我就不给出具体的包了。
layim 官网
- https://layuion.com/layim/
1、引入 layIM
首先引进相关 layim 模块插件,这个插件不是开源的,线上使用需要进行捐赠,如果需要在商业中使用最好进行捐赠哈。
然后按照官网给出的例子,我们来搞个最简单的 hello word。在这之前,我们先要获取一下插件,原则上我们应该通过捐赠形式获取,不过只为了学习,所以就直接从网络上搜索了一个,相关的 js 如下:
将 layim.js 导入到 resourcesstatic eslayuilaymodules 目录下
将 layim 样式文件夹 导入到 resourcesstatic eslayuicssmodules 目录下
2、编写demo
然后根据官方文档,我们在首页的正下方有个群聊按钮,点击之后可以打开群聊窗口进行群聊。所以为了所有页面都能聊天,所以把 js 写在全局模板中
- templates/inc/layout.ftl
这段 js 的效果如下,我们来分析一下:
- layim.config 表示进行初始化配置
- brief: true 表示简约模式,只有一个聊天窗口
- .chat 是声明并打开一个聊天窗口
- layim.setChatMin(); 表示收缩聊天面板。
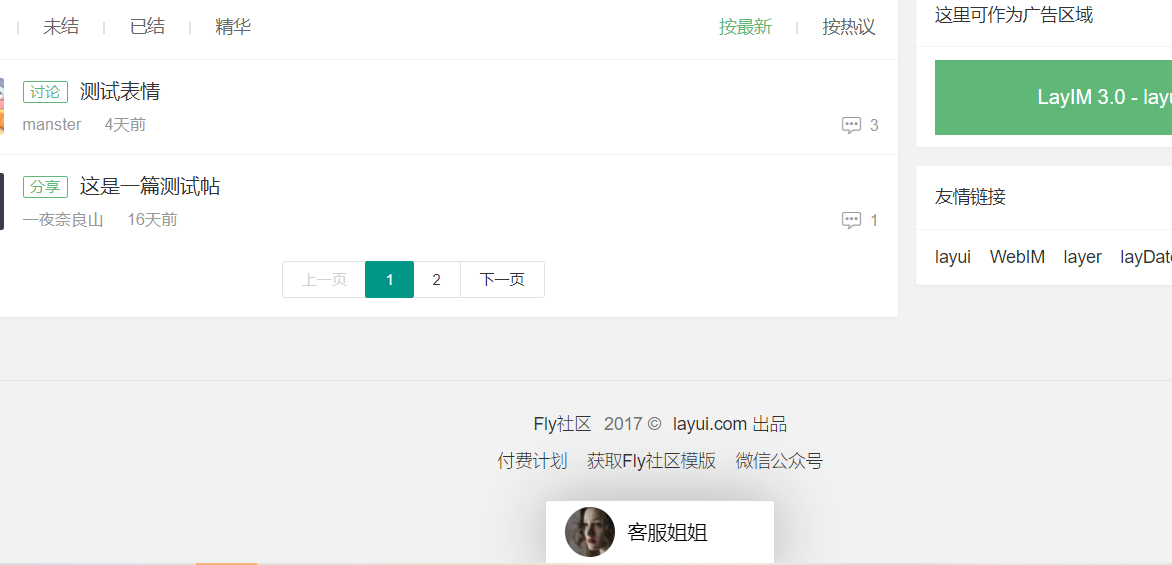
点击之后的效果:
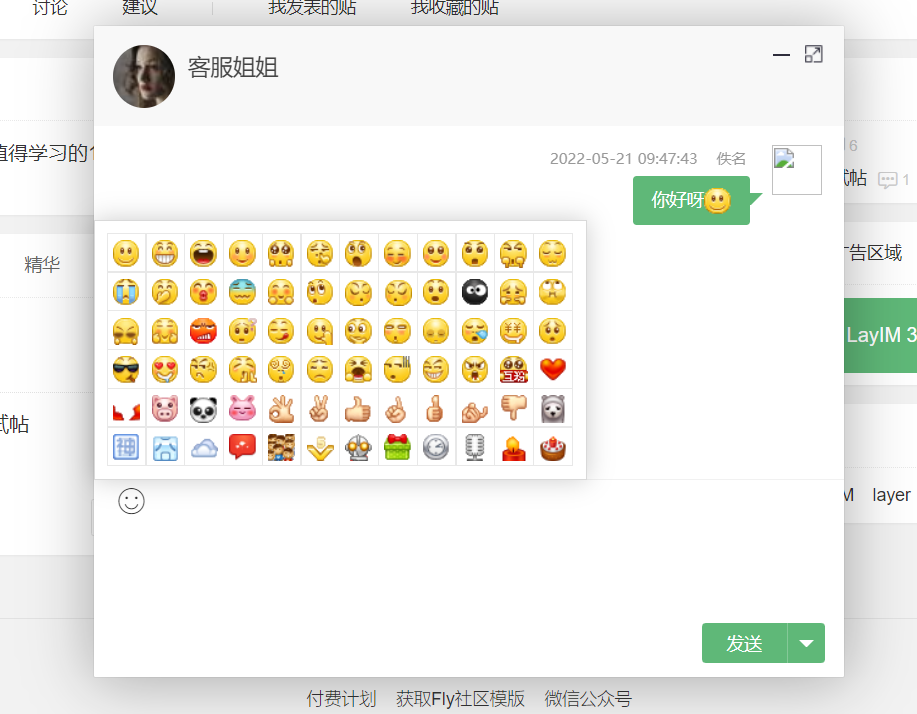
ok,上面是我们最简单的一个聊天窗口已经可以展示出来了,不过现在还没有功能,还不能相互聊天,接下来我们会给每个窗口一个身份,然后进行相互聊天。
2、封装js
我们在 resourcesstatic esjs 目录下新建一个 chat.js来进行封装
然后在 layout.ftl 中进行引入
然后我们分析一下要做的事情
- 建立 ws 连接
- 历史聊天信息回显
- 获取个人、群聊信息并打开聊天窗口
- 发送消息
- 接受消息
- 心跳、断开重连机制
由于这些方法有的需要相互调用,所以我们最好再建一个 js 文件进行封装,方便我们调用,创建 im.js,将其也导入 layout.ftl
3、t-io 集成 websocket
1、tio简介
(初始化服务器)
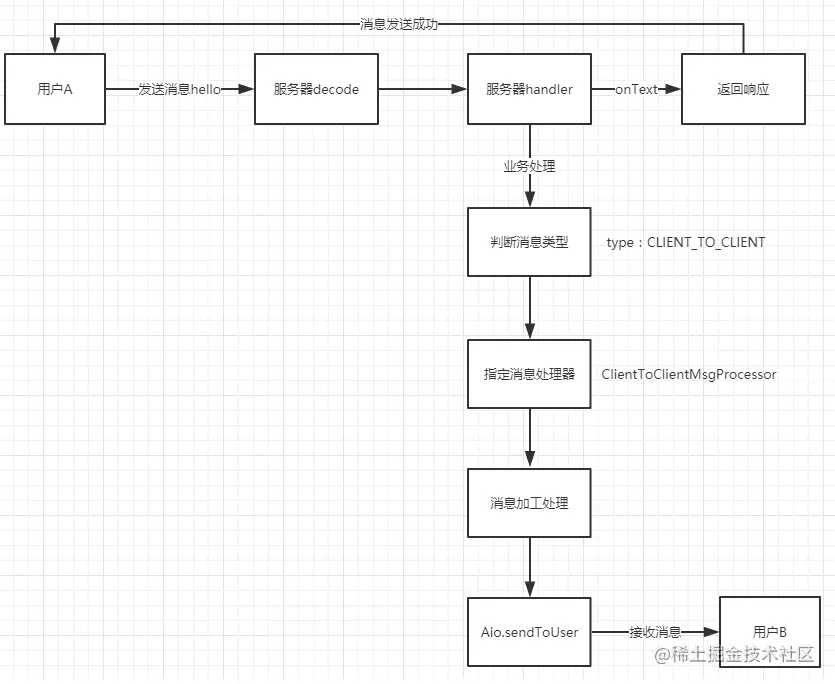
(客户端与服务端通讯流程)
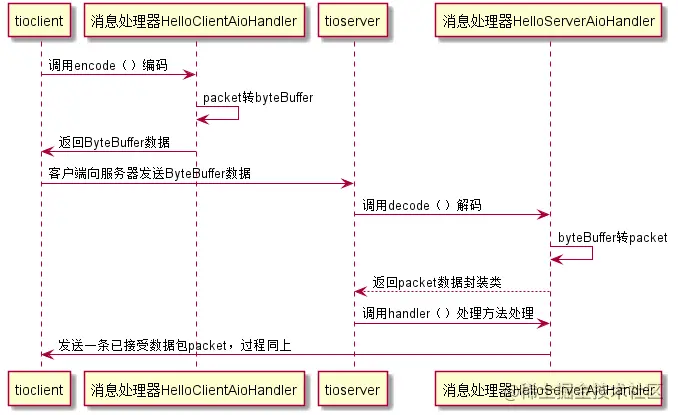
然后集成 t-io 之后要去实现的消息逻辑处理:
常用类说明:
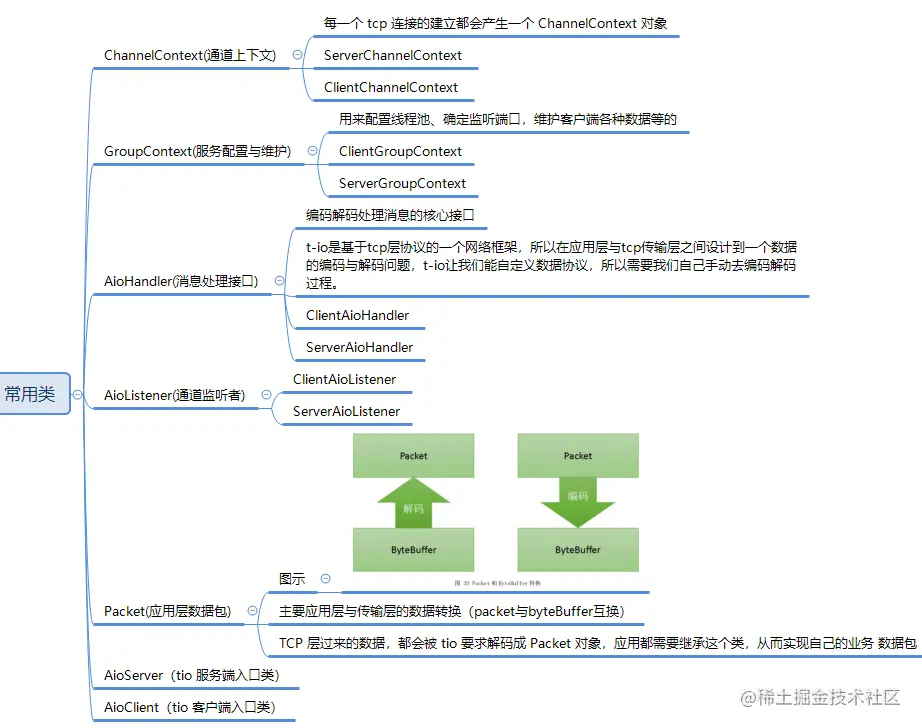
通过以上内容我们知道了几个比较关键的类,也是我们再初始化启动 t-io 服务的几个关键类。
我们先来说明一下几个比较重要的类
-
(握手、消息处理类)
- 这个是消息处理的接口,包括握手时、握手完成后、消息处理等方法
- 会在 中调用,而这个类实现了 。里面有我们熟悉的 、、 三个方法。
-
(ws 服务启动类)
- 针对 ws,tio 封装了很多涉及到的东西使配置更加简便,他的 start 方法中可以看出其实就是我们熟悉的 。
-
(配置类)
- 这个我们就比较熟悉了,服务端的配置类,可以配置心跳时间等。
以上就是我们需要清楚的 3 个类。有了这 3 个类之后我们就可以启动我们的服务,进行 ws 的连接了。
2、集成
因为我们这次要实现的功能是 t-io 集成 websocket。而 t-io 为我们已经帮我们集成了一套代码,帮我们省去了协议升级等步骤,这样我我们就不需要去手动写很多升级协议等代码了。
我们接着集成 t-io 的 websocket。因为是直接有一套集成框架,所以我这里直接引入版本:https://mvnrepository.com/artifact/org.t-io/tio-websocket-server
4、实现
首先我们整理一下思路
- 后端服务
- 我们需要一个配置 ,将启动类进行初始化
- 启动类需要端口号和消息的处理器()
- 消息处理器中需要鉴别消息类型,对此我们写一个 ,使用 map 来进行存储与鉴别
- 而真正进行消息处理我们就在 中
- 握手前 ,我们获取用户的 id 来绑定个人通道
- 握手后 ,我们将根据群聊名来绑定群聊通道
- 在接受消息时 ,我们将其传输来的 JSON 数据转化为 map 进行接收,然后根据 获取消息类型对应的处理器,然后调用处理器的处理方法 来进行处理
- , 我们就简单打印一下
- , 我们对消息进行一些处理。
- 首先我们还是将数据由 json 转为 map,获取发送用户与接受目标
- 然后装载实体
- 其次将消息进行发送到群聊,在发送时我们需要一个过滤器,不将群组消息发送到自己所在的通道(因为 layim 会自动将自己发送的消息直接显示,我们将不需要后端再给自己显示一遍了)
- 最后我们将该条消息存入 redis,方便查看聊天历史记录
- 前端
- 首先我们使用 layui 的 layim 组件,而我们需要的许多方法之间需要互相调用,为了方便调用我们再封装一个 js 来编写方法
- 该对象中,我们首先需要进行获取个人、群聊信息,并打开聊天窗口
- 然后我们需要进行与后端 tio 建立连接,主要包括 ,, 三个方法,同时我们也要设计心跳消息与重连
- 其次我们实现消息的发送
- 最后我们实现历史聊天记录的回显
1、后端服务
首先我们需要对 tio 服务进行配置启动
关于以上这段配置,我们需要三个东西,首先就是配置端口,然后是启动器 ,最后是 消息分类处理器
我们在 application.yml 中进行消息处理的端口配置
- ImServerStarter
这里我们首先需要我们的 tio 服务进行启动
根据以上代码,我们又需要一个消息处理器,也就是关于消息的处理器
- ImWsMsgHandler
其中 为我们要对消息进行处理的地方,比如握手前,握手后,接受消息,关闭时要进行的操作
- MsgHandlerFactory
然后我们需要进行初始化消息处理器类别,也就是判别传来的消息是一个什么类型的,我们针对类型进行不同的处理
比如 ping 心跳,就不进行处理,或者只进行日志的打印;但是针对 chat 型消息,我们需要对其进行转换、发送等处理。
- ,消息处理接口
- ,ping 消息处理器
- chat 消息处理器
其中的 ChatInMess,ChatOutMess,ImUser,ImTo,ImMess 都是根据 layim 传来的消息或者接受的接口类型进行封装接受的实体类
在群聊时,我们自己发送的消息直接根据前端显示,所以我们自己就不需要后端传递来的消息了,对此我们在发送群组消息时进行过滤,在发送群组消息时,我们不给自己这一个成员发送消息 。
然后当我们在查看历史消息的时候,我们需要一些历史消息,我们就在 redis 中存储一段时间
而由于我们的 没有被 spring 管理,所以我们需要 工具类去 spring 中获取到我们的 ,我们也为这个实现类自己命名
至此消息的后端处理便完成了。
2、前端处理
首先我们根据 layui 的 layim 开发文档进行调用
然后我们真正开始实现这些方法。
首先为了方便调用我们将这个 js 写为一个对象,然后编写其构造方法
首先我们与后端建立连接,并实现监听的方法
其中,这时我们就可以进行心跳消息的发送了
然后我们进行获取个人的信息,群聊信息并打开聊天窗口
在后端我们也进行相应的接口编写,并赋予默认值
我们实现获取用户信息的接口,
然后我们实现消息的发送
最后我们实现前端的历史消息回显
后端也编写相应的接口
实现获取历史聊天记录,而我们在 tio 返回消息的时候就已经将消息都存入 redis 中,所以我们直接取出即可
总体的 如下:
登录
注册
首页
个人中心 
搜索
聊天
聊天历史 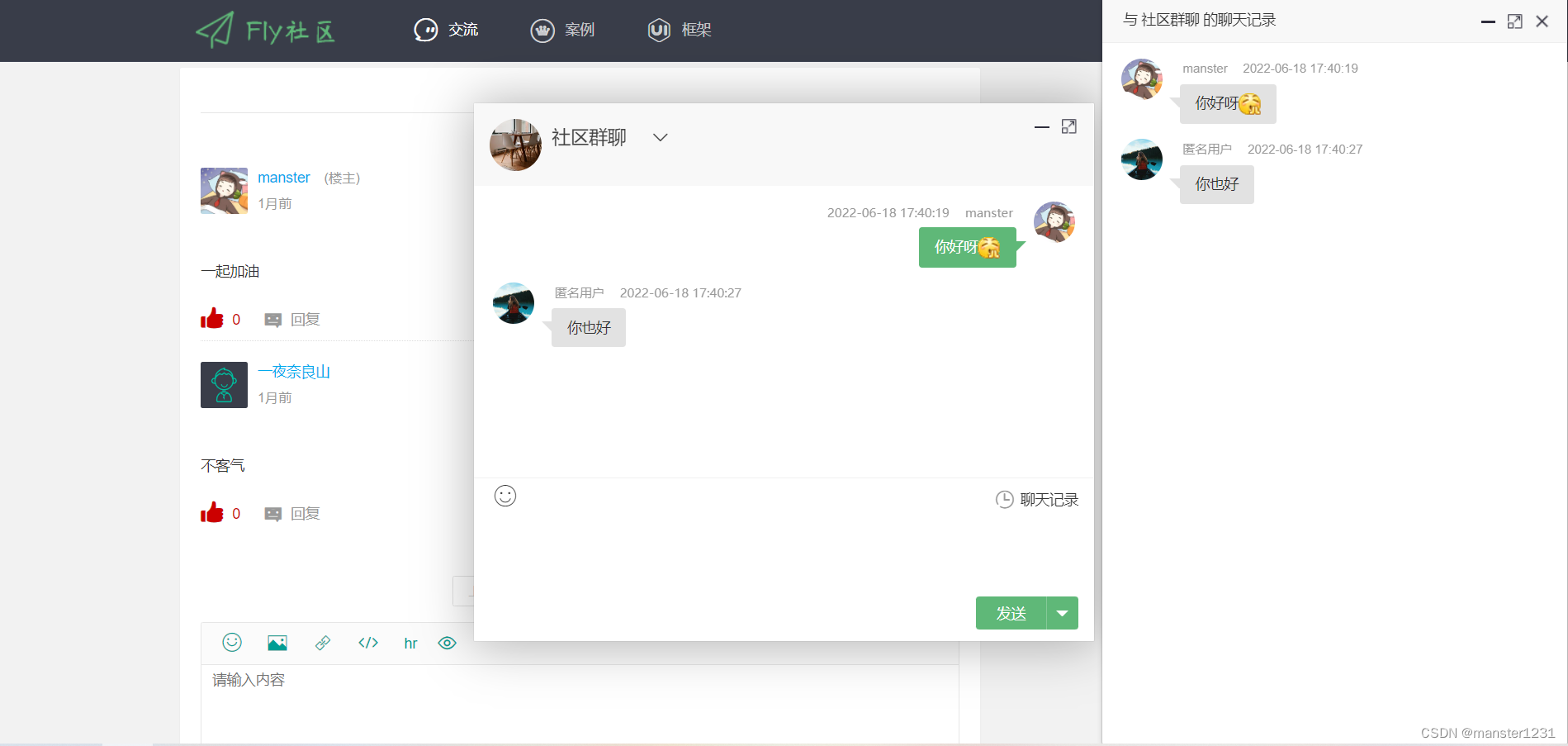
博客详情